内存优化实战:从数据结构选择到GC策略
内存优化实战:从数据结构选择到GC策略
dong4j内存优化对比
数据量
外呼名单 10 万
白名单 100 万
黑名单 500 万
JVM 参数
1 | -verbose:gc |
优化之前
对比耗时
1 | 2018-05-31 15:29:49 [INFO]] [pool-1-thread-1] [parseRegulation] 白名单匹配个数 = 25 |
内存消耗
启动时第一次运行解析任务, 并且符合条件的 calloutList 为 99810;
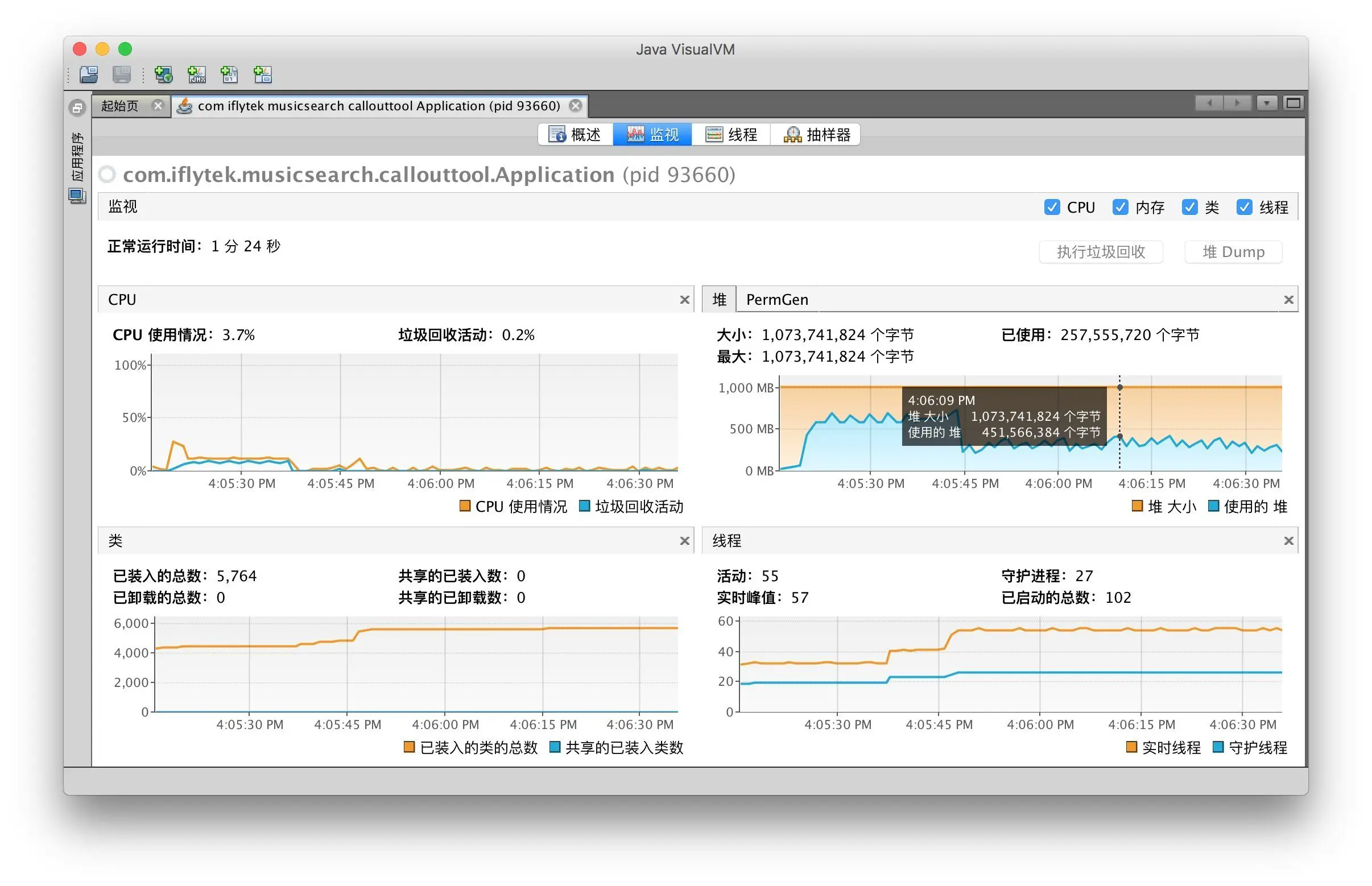
最高使用 762.5 M
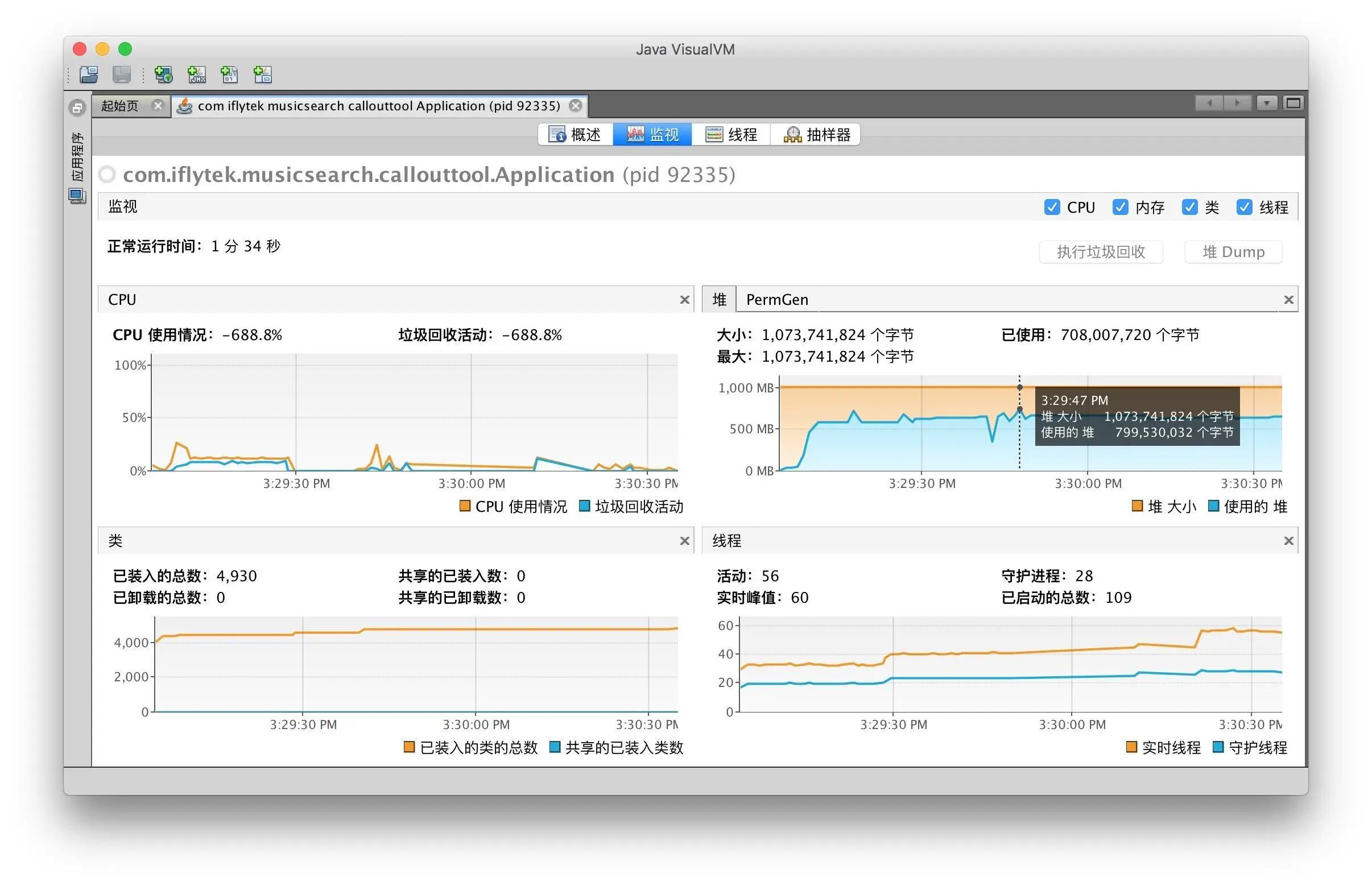
持续运行一段时间, 并且使用相同的号码包进行测试的结果
发生了 OOM
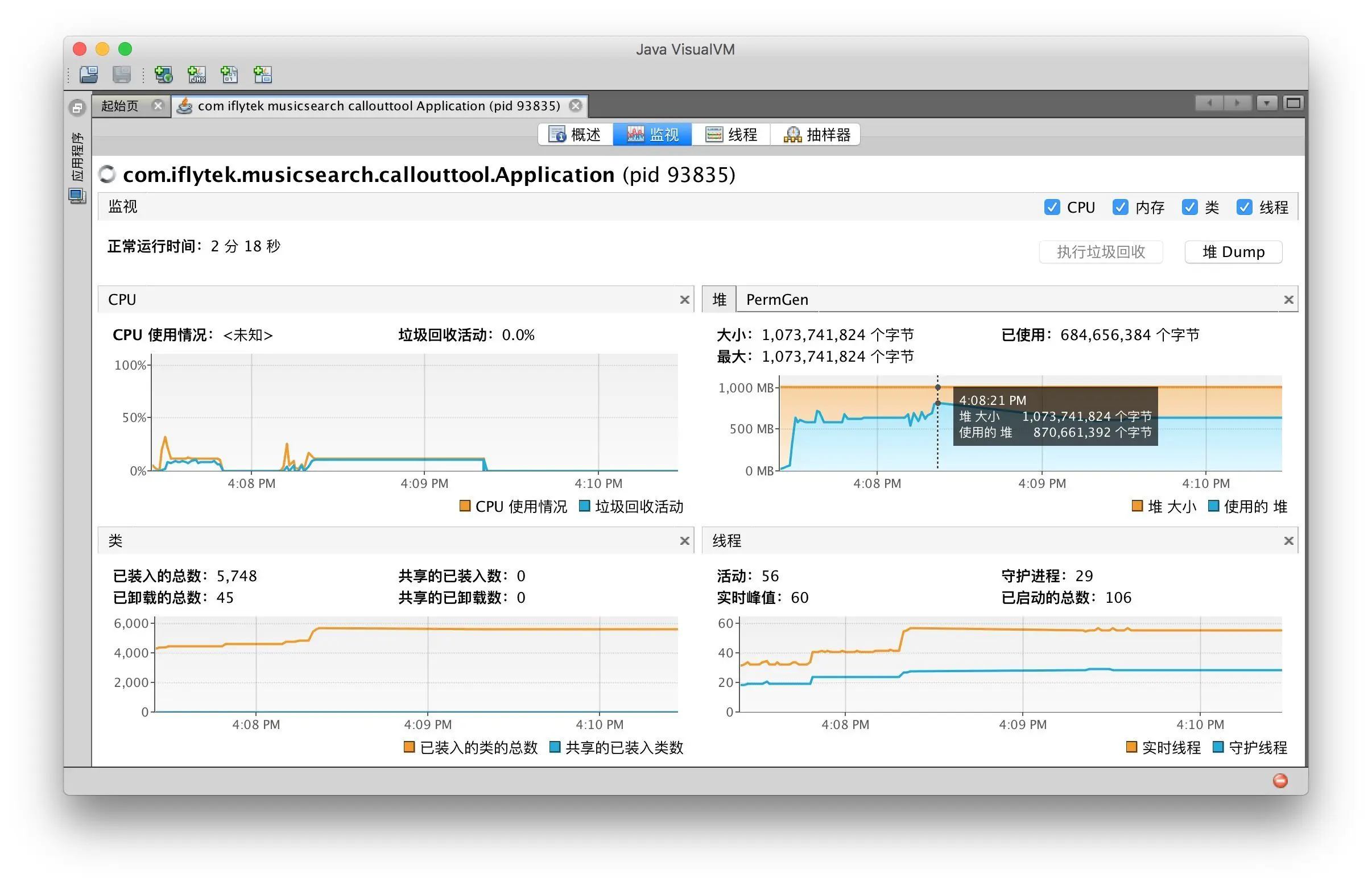
优化之后
对比耗时
1 | 2018-05-31 15:46:45 [INFO]] [pool-1-thread-1] [dealWhiteAndBlackList] 白名单匹配个数 = 25 |
内存消耗
启动时第一次运行解析任务, 并且符合条件的 calloutList 为 99810;
最高 728 M
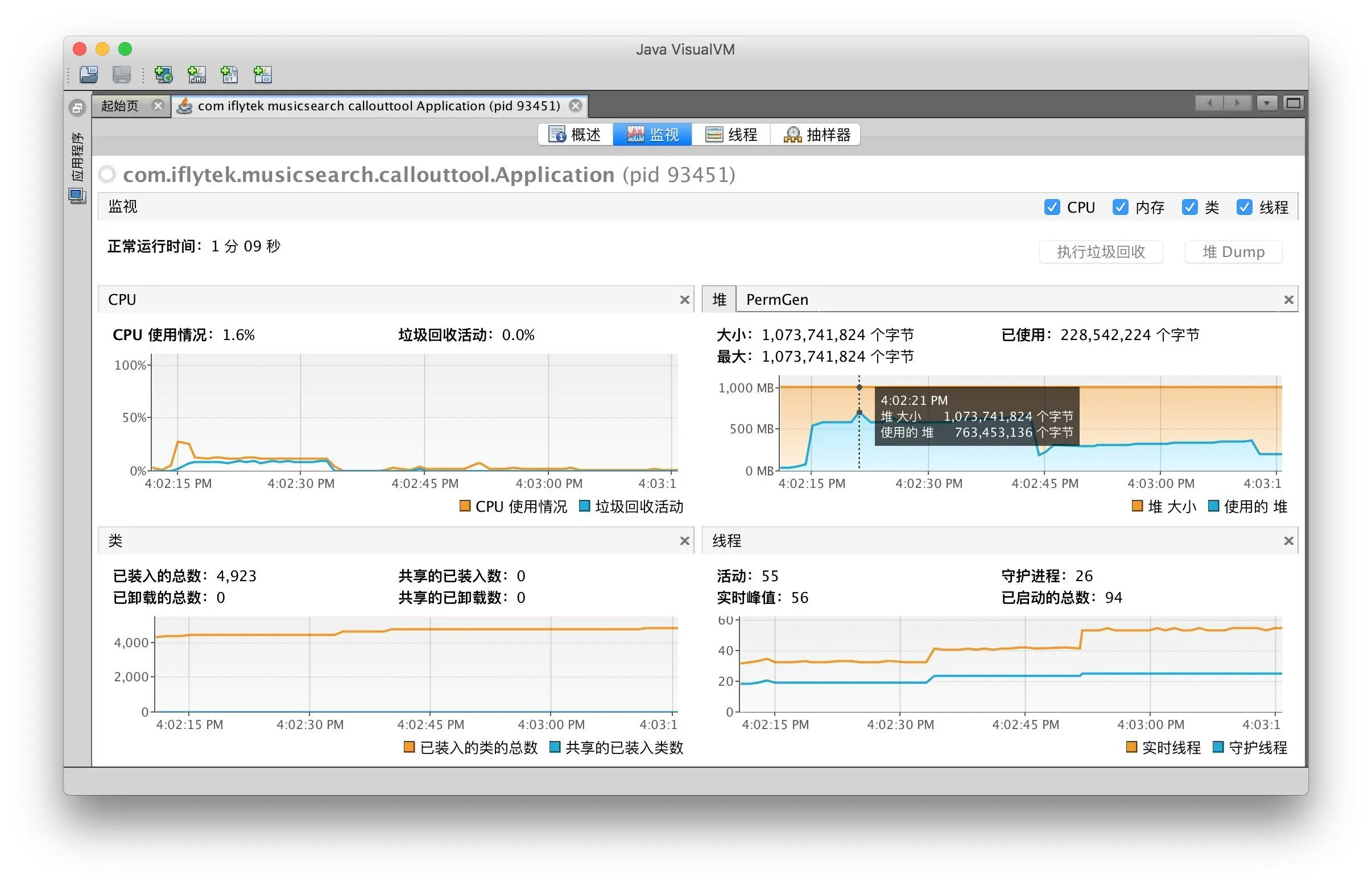
持续运行一段时间, 并且使用相同的号码包进行测试的结果
优化方案
- 使用 BloomFilter 代替 DataCache 来存储黑白名单;
- 及时清理占用大内存的临时变量;
布隆过滤器
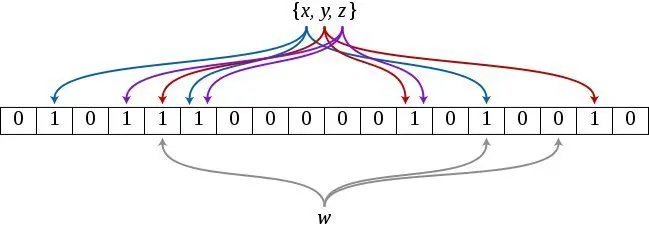
简介:
是一个很长的二进制向量和一系列随机映射函数. 布隆过滤器可以用于检索一个元素是否在一个集合中. 它的优点是空间效率和查询时间都远远超过一般的算法,
缺点是有一定的误识别率和删除困难.
原理:
当一个元素被加入集合时, 通过 K 个散列函数将这个元素映射成一个位数组中的 K 个点, 把它们置为 1. 检索时,
我们只要看看这些点是不是都是 1 就(大约)知道集合中有没有它了: 如果这些点有任何一个 0, 则被检元素一定不在;如果都是 1, 则被检元素很可能在.
优点:
相比于其它的数据结构, 布隆过滤器在空间和时间方面都有巨大的优势. 布隆过滤器存储空间和插入/查询时间都是常数(O(k)). 而且它不存储元素本身,
在某些对保密要求非常严格的场合有优势.
缺点:
一定的误识别率和删除困难.
开发建议
程序的运行会直接影响系统环境的变化, 从而影响 GC 的触发. 若不针对 GC 的特点进行设计和编码, 就会出现内存驻留等一系列负面影响.
为了避免这些影响, 基本的原则就是尽可能地减少垃圾和减少 GC 过程中的开销. 具体措施包括以下几个方面:
不要显式调用
System.gc()此函数建议 JVM 进行主 GC, 虽然只是建议而非一定, 但很多情况下它会触发主 GC, 从而增加主 GC 的频率, 也即增加了间歇性停顿的次数.
尽量减少临时对象的使用
临时对象在跳出函数调用后, 会成为垃圾, 少用临时变量就相当于减少了垃圾的产生.
对象不用时最好显式置为 null
一般而言, 为 null 的对象都会被作为垃圾处理, 所以将不用的对象显式地设为 null, 有利于 GC 收集器判定垃圾, 从而提高了 GC 的效率.
尽量少用静态对象变量
静态变量属于全局变量, 不会被 GC 回收, 它们会一直占用内存.