在 Docker 中部署 PostgresML 实现数据库内机器学习

在 Docker 中部署 PostgresML 实现数据库内机器学习
dong4j'/%3E%3Cpath d='M0 560 220 420l160 96 210-220 250 248 160-120 280 164v132H0z' fill='%23d9e1ee'/%3E%3Ccircle cx='980' cy='210' r='72' fill='%23d2dbea'/%3E%3C/svg%3E)
背景
随着人工智能技术的快速发展,Java 开发者也在积极探索如何将 AI 能力集成到企业级应用中。Spring 团队发布的 Spring AI 项目为 Java 生态带来了强大的 AI 集成能力。特别是 Spring AI 1.1.0 版本的正式发布,使得使用 Java 开发 AI 应用变得更加便捷。
在 AI 应用开发中,向量数据库扮演着重要角色,特别是在处理文本嵌入和语义搜索场景下。PostgresML 作为一个强大的 PostgreSQL 扩展,能够直接在数据库内部实现机器学习功能,为 AI 应用提供了高效的向量存储和检索能力。
本文将详细介绍如何在 Docker 环境中部署和配置 PostgresML,为后续的 AI 应用开发打下坚实基础。
简介
PostgresML 是一个强大的 PostgreSQL 扩展,它将机器学习功能直接集成到数据库内部。通过 pgml 扩展,开发者可以在数据库层面实现文本嵌入、语义搜索等 AI 功能,无需额外的外部服务依赖。
在 Docker 容器中部署 PostgresML 具有以下优势:
- 环境一致性:确保开发、测试和生产环境的一致性
- 快速部署:通过预构建镜像快速启动服务
- 资源隔离:容器化部署便于资源管理和隔离
- 易于维护:简化的升级和备份流程
本指南将详细介绍如何在 Docker 环境中部署 PostgresML,包括镜像拉取、容器配置、扩展启用以及实际应用示例,帮助读者快速掌握这一强大的数据库内 AI 解决方案。
PostgresML 核心功能
PostgresML 为 PostgreSQL 数据库带来了强大的机器学习能力,让开发者能够通过标准 SQL 语法直接在数据库内部执行 AI 相关操作。以下是其核心功能特性:
内置机器学习模型
PostgresML 集成了多种预训练模型,包括:
- 文本嵌入模型:如
sentence-transformers/all-MiniLM-L6-v2,用于生成语义向量 - 多语言支持:支持中文、英文等多种语言的文本处理
- 分类模型:支持文本分类、情感分析、垃圾邮件检测等任务
- 回归模型:用于数值预测、评分等场景
- 自定义模型:支持导入和训练自定义的机器学习模型
向量存储与检索
通过集成 pgvector 扩展,PostgresML 提供了高效的向量存储和相似性搜索功能:
- 高维向量支持:支持最高 2000 维的向量数据存储
- 多种相似性度量算法:
- 余弦距离(Cosine Distance):适合文本相似度计算
- 欧氏距离(Euclidean Distance):适合数值型向量比较
- 曼哈顿距离(Manhattan Distance):适合特定场景的向量比较
- 索引优化:
- IVFFlat(Inverted File Flat):适合大规模数据集的近似搜索
- HNSW(Hierarchical Navigable Small World):适合高精度搜索
- 支持并行索引创建,提升构建效率
简化的工作流程
- 一站式解决方案:无需外部服务依赖,所有操作都在数据库内完成
- 标准 SQL 接口:降低学习成本,开发者可以使用熟悉的 SQL 语法
- 自动模型管理:自动下载和缓存所需的机器学习模型
- 事务安全:所有机器学习操作都在数据库事务中执行,确保数据一致性
- 权限控制:基于 PostgreSQL 的角色权限系统,确保数据安全
高性能处理
- CPU/GPU 加速支持:充分利用硬件资源提升处理速度
- 批量处理优化:支持大规模数据的高效处理
- 内存优化:智能内存管理确保稳定运行
- 并行计算:支持多线程并行处理,提升计算效率
- 缓存机制:模型和计算结果缓存,减少重复计算开销
企业级特性
- 高可用性支持:支持 PostgreSQL 的高可用部署方案
- 备份恢复:与 PostgreSQL 备份机制完全兼容
- 监控集成:支持 PostgreSQL 的监控工具和指标
- 扩展性:支持水平扩展和垂直扩展
- 安全合规:符合企业数据安全要求
这些功能使 PostgresML 成为企业级 AI 应用的理想选择,特别适用于需要高性能向量检索和文本分析的场景。
步骤 1:拉取 PostgresML Docker 镜像
首先从 GitHub Container Registry 拉取官方的 PostgresML Docker 镜像。2.10.0 版本是一个稳定的发行版,预装了 PostgreSQL 15 和 pgml 扩展。
镜像版本说明
PostgresML 提供多个版本,每个版本都有其特定的功能和兼容性:
- 2.10.0:稳定版本,包含 PostgreSQL 15 和完整的机器学习功能
- 2.8.x:最新版本,可能包含新功能和性能优化
- 2.6.x:旧版本,适用于需要向后兼容的场景
拉取镜像
1 | docker pull ghcr.io/postgresml/postgresml:2.10.0 |
镜像组成
PostgresML 镜像包含以下组件:
- PostgreSQL 15:作为数据库引擎
- pgml 扩展:核心机器学习功能
- pgvector 扩展:向量数据类型和相似性搜索
- Python 环境:用于运行机器学习模型
- 预训练模型:常用的文本嵌入和分类模型
- 控制面板:Web 界面用于管理和监控
验证镜像
拉取完成后,可以通过以下命令验证镜像是否成功下载:
1 | docker images | grep postgresml |
预期输出:
1 | REPOSITORY TAG IMAGE ID CREATED SIZE |
镜像详细信息
查看镜像的详细信息:
1 | docker inspect ghcr.io/postgresml/postgresml:2.10.0 |
这个命令会显示镜像的配置信息,包括:
- 环境变量
- 端口配置
- 数据卷挂载点
- 启动命令
- 健康检查配置
镜像大小考虑
PostgresML 镜像相对较大(约 1.2GB),主要因为:
- 包含完整的 PostgreSQL 数据库
- 预装了多个机器学习模型
- 包含 Python 运行时环境
- 集成了各种依赖库
在生产环境中,建议:
- 使用镜像仓库进行本地缓存
- 考虑使用多阶段构建优化镜像大小
- 定期更新镜像以获取安全补丁
步骤 2:创建 Docker 卷
为了确保 PostgreSQL 数据在容器重启或删除后仍然得以保留,我们需要创建一个 Docker 卷来持久化存储数据。
Docker 卷的优势
使用 Docker 卷进行数据持久化具有以下优势:
- 数据持久性:容器删除后数据仍然保留
- 性能优化:直接绑定到主机文件系统,性能优于容器内存储
- 备份便利:可以轻松备份和恢复数据
- 跨容器共享:多个容器可以共享同一个数据卷
- 管理简单:Docker 提供了完整的卷管理命令
创建数据卷
1 | docker volume create pgml_data |
验证卷创建
创建完成后,可以通过以下命令验证卷是否创建成功:
1 | docker volume ls | grep pgml_data |
预期输出:
1 | DRIVER VOLUME NAME |
查看卷详细信息
1 | docker volume inspect pgml_data |
输出示例:
1 | [ |
卷的存储位置
- Linux:
/var/lib/docker/volumes/pgml_data/_data - macOS:
~/Library/Containers/com.docker.docker/Data/volumes/pgml_data/_data - Windows:
C:\Users\[username]\AppData\Local\Docker\volumes\pgml_data\_data
卷管理最佳实践
- 命名规范:使用有意义的名称,如
pgml_data、pgml_backup等 - 定期清理:删除不再使用的卷以释放磁盘空间
- 备份策略:定期备份卷数据到外部存储
- 权限管理:确保容器有正确的读写权限
清理未使用的卷
1 | 查看所有卷 |
高级配置
对于生产环境,可以考虑以下高级配置:
1 | 创建具有特定驱动程序的卷 |
这个卷将在后续步骤中挂载到容器的 /var/lib/postgresql 目录,确保数据库文件得到持久化存储。在生产环境中,建议定期备份这个卷以防止数据丢失。
步骤 3:运行 PostgresML 容器
现在我们可以启动 PostgresML 容器了。在运行命令中,我们将:
- 将之前创建的
pgml_data卷挂载到容器的/var/lib/postgresql目录以持久化数据 - 将容器的 5432 端口映射到主机的 5434 端口,避免与本地 PostgreSQL 实例冲突
- 将容器的 8000 端口映射到主机的 8888 端口,用于访问 PostgresML 控制面板
- 设置 PostgreSQL 的
postgres用户密码
基础运行命令
1 | docker run -d \ |
注意:请将
secure_password_here替换为你自己的强密码。启动成功后访问 控制台: http://127.0.0.1:8888/engine/notebooks
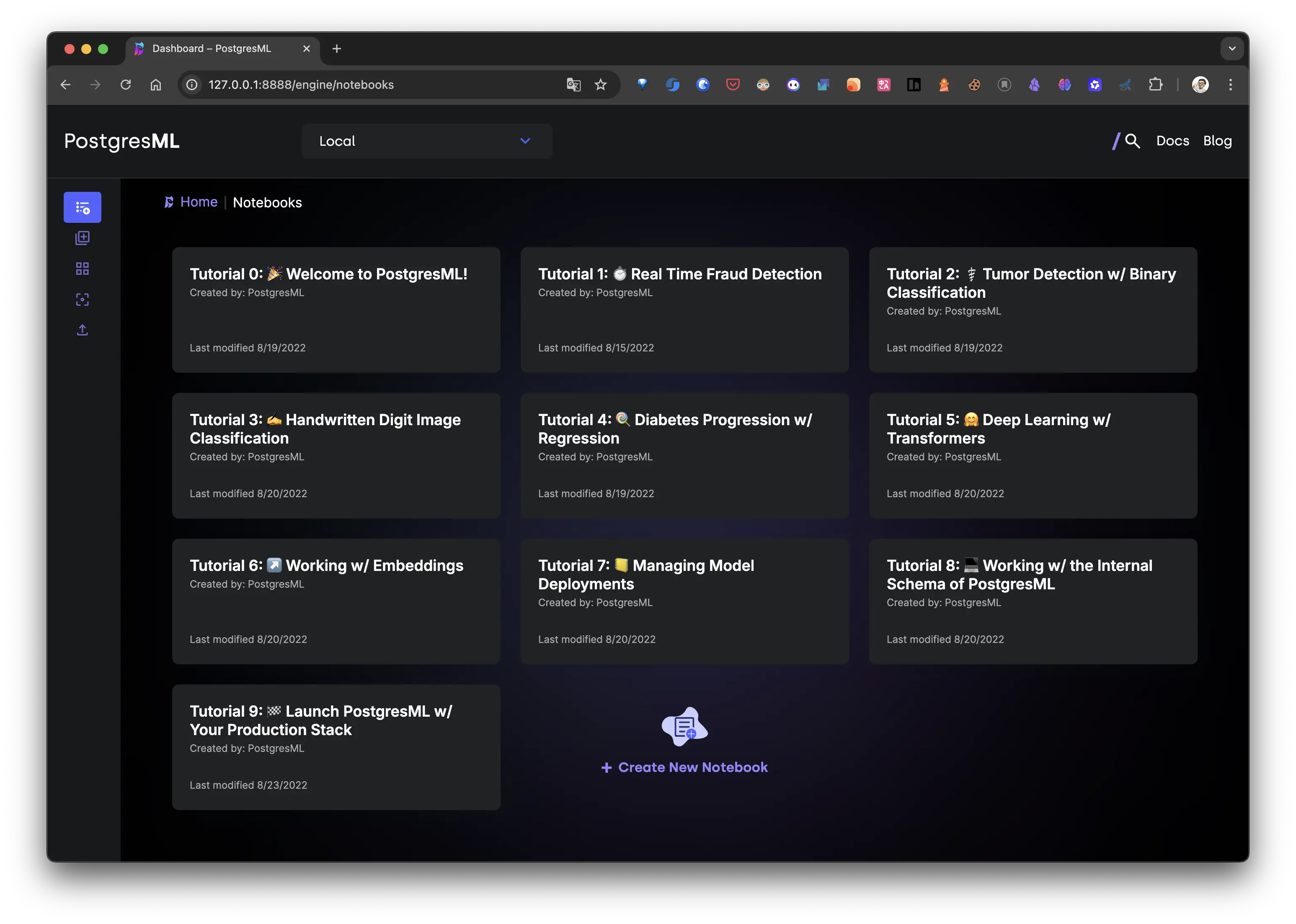
Docker-compose:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
pgml_postgres:
image: ghcr.io/postgresml/postgresml:2.10.0
container_name: pgml_postgres
environment:
POSTGRES_PASSWORD: secure_password_here
ports:
- "5434:5432"
- "8888:8000"
volumes:
- pgml_data:/var/lib/postgresql
command: tail -f /dev/null
restart: unless-stopped
volumes:
pgml_data:
参数详解
-d:后台运行容器--name pgml_postgres:为容器指定名称-v pgml_data:/var/lib/postgresql:挂载数据卷-p 5434:5432:端口映射(主机:容器)-p 8888:8000:控制面板端口映射-e POSTGRES_PASSWORD:设置数据库密码
生产环境增强配置
对于生产环境,建议使用以下增强配置:
1 | docker run -d \ |
资源限制说明
--memory=4g:限制容器内存使用为 4GB--cpus=2.0:限制容器使用 2 个 CPU 核心--restart=unless-stopped:容器停止时自动重启--health-*:健康检查配置
验证容器状态
启动容器后,等待片刻让服务完全启动,然后通过以下命令确认容器正在运行:
1 | docker ps | grep pgml_postgres |
预期输出:
1 | CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES |
查看容器日志
你也可以通过查看容器日志来确认服务启动情况:
1 | docker logs pgml_postgres |
在日志中应该能看到类似以下的成功启动信息:
1 | Starting PostgresML |
健康检查
查看容器健康状态:
1 | docker inspect pgml_postgres --format='{{.State.Health.Status}}' |
调试模式
如果遇到容器启动问题,可以尝试以下命令来保持容器运行以便调试:
1 | docker rm -f pgml_postgres |
使用 tail -f /dev/null 命令可以让容器保持运行状态,方便后续进入容器进行故障排查。
进入容器调试
1 | docker exec -it pgml_postgres bash |
在容器内,你可以:
- 检查 PostgreSQL 配置文件
- 查看日志文件
- 执行数据库命令
- 检查扩展安装状态
容器管理命令
1 | 停止容器 |
步骤 4:连接到数据库
现在我们可以通过 psql 客户端连接到 PostgreSQL 数据库。首先连接到默认的 postgres 数据库:
1 | psql -h localhost -p 5434 -U postgres -d postgres |
系统会提示输入密码,请输入在步骤3中设置的密码。
或者直接使用 DataGrip
连接成功后,默认已经为机器学习任务创建一个专门的数据库:
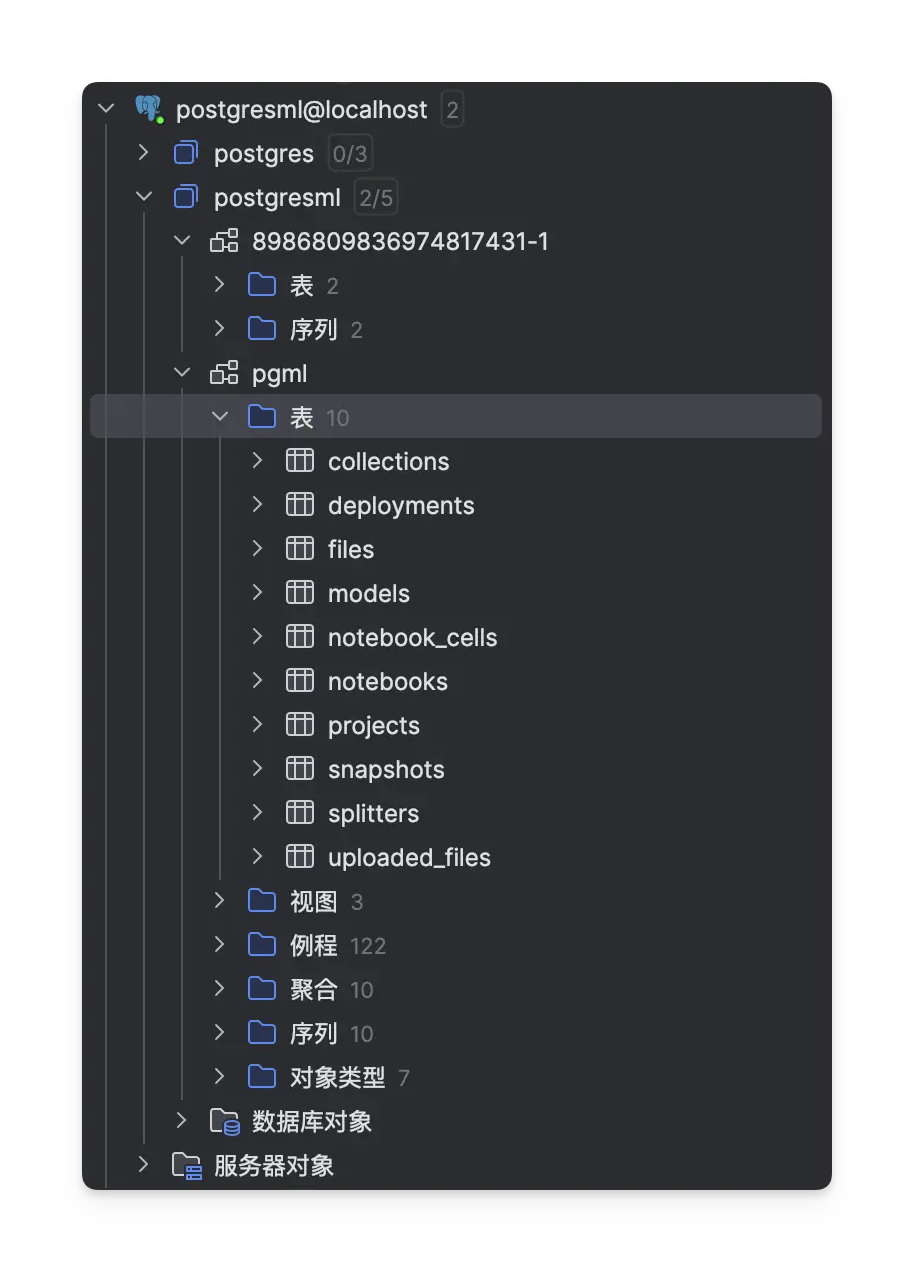
然后连接到新创建的数据库:
1 | psql -h localhost -p 5434 -U postgres -d postgresml |
故障排除
如果遇到身份验证失败的问题,可能需要检查容器中的 pg_hba.conf 配置文件:
1 | docker exec -it pgml_postgres bash |
确保配置文件中包含以下行以允许网络连接:
1 | host all all 0.0.0.0/0 md5 |
如果缺少此配置,需要添加并重新加载 PostgreSQL 配置:
1 | 在容器内执行 |
然后重新尝试连接数据库。
步骤 5:启用 pgml 和 vector 扩展
连接到 postgresml 数据库后,我们需要启用 PostgresML 和 pgvector 扩展:
首先查看一下默认的扩展信息:
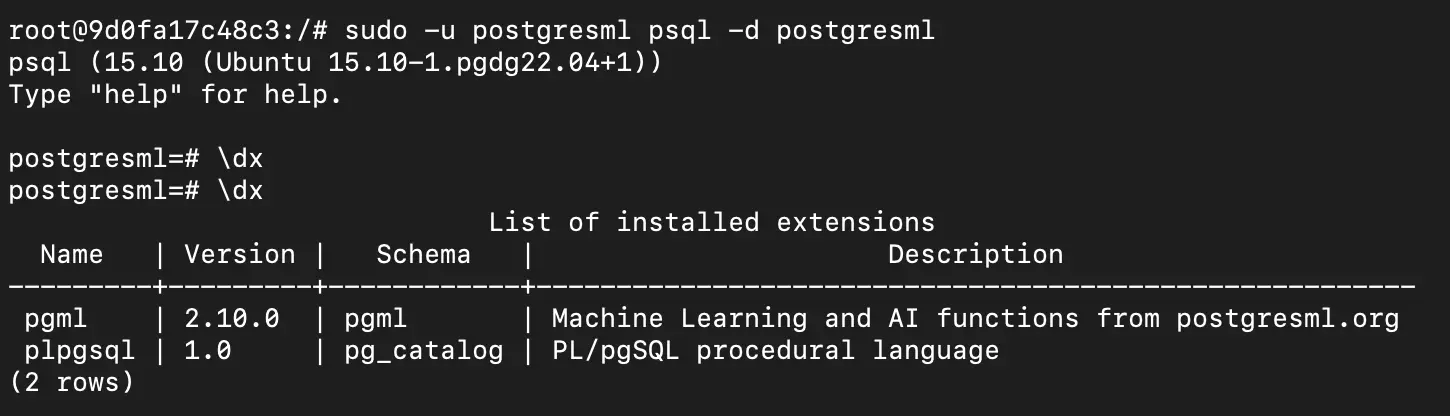
1 | # 已经存在了不需要创建了 |
可以通过以下命令验证扩展是否成功安装:
1 | \dx |
预期输出:
1 | List of installed extensions |
这两个扩展各自承担不同的功能:
pgml扩展提供了机器学习功能,包括文本嵌入、模型推理等, 比如:1
2
3
4
5
6# 用 SQL 调用 LLM
SELECT pgml.chat('gpt-4', '写一段 SQL 连接示例');
# 文本 embedding
SELECT pgml.embed('voyage-2-lite', 'hello world');
# 模型列表
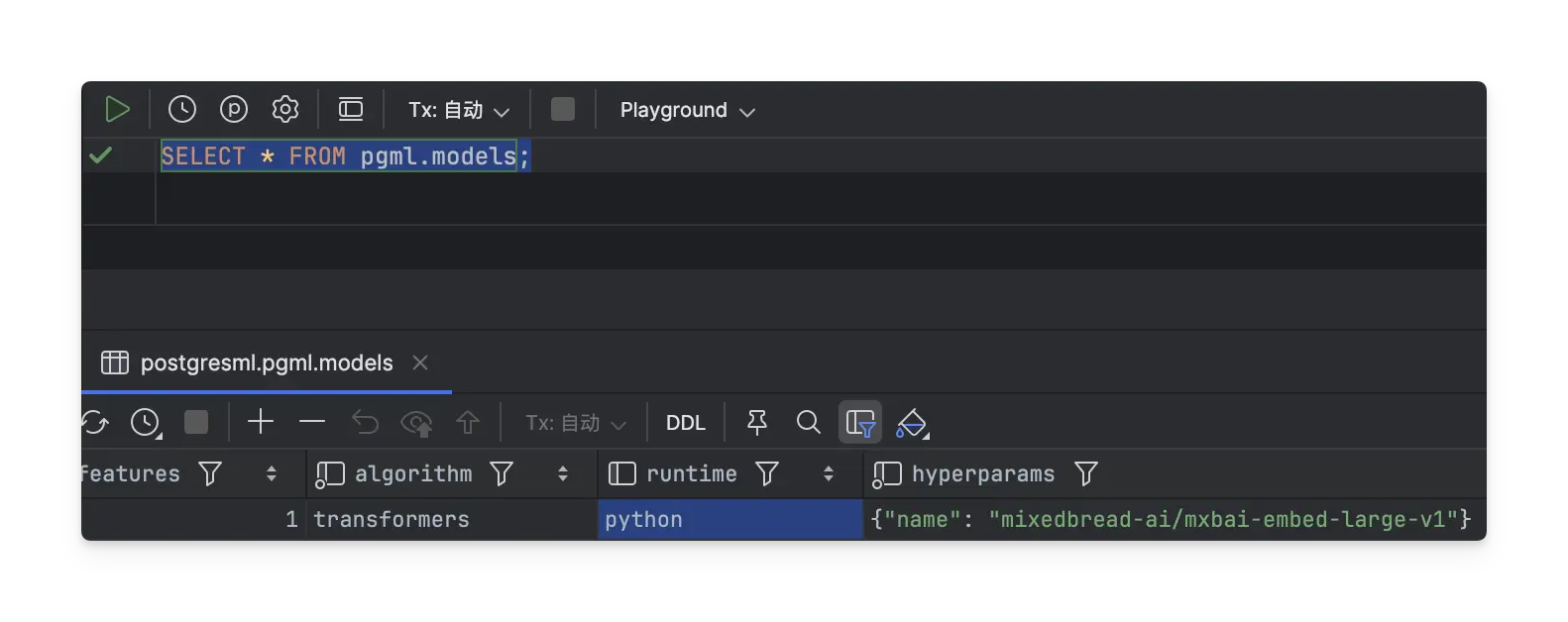
SELECT * FROM pgml.models;默认自带一个 embedding 模型:
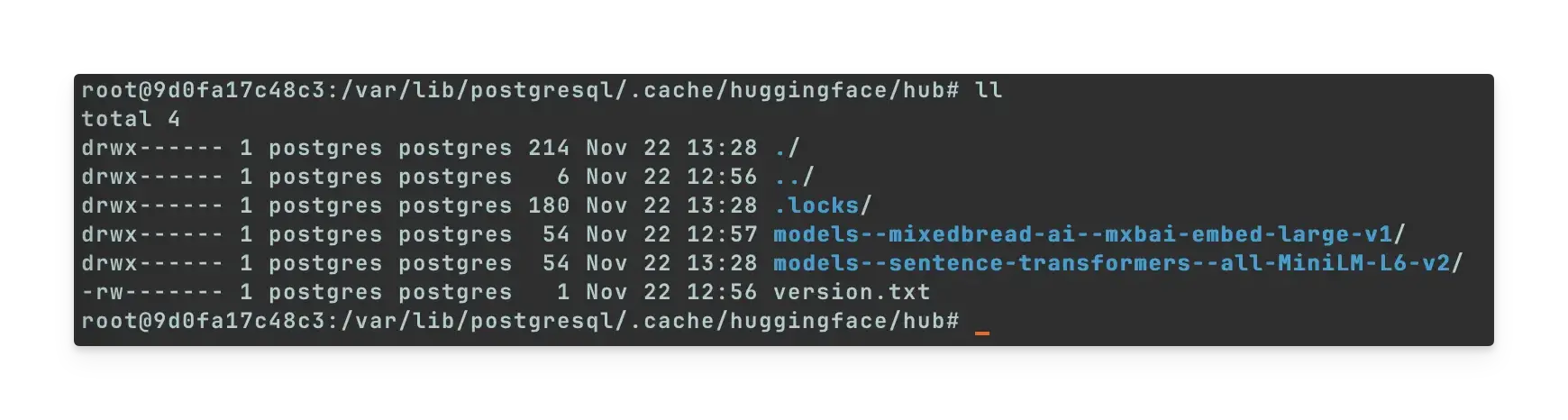
模型下载位置:
/var/lib/postgresql/.cache/huggingface(models--sentence-transformers--all-MiniLM-L6-v2是后续步骤下载的, 这里是补录的图片, 默认只有models--mixedbread-ai--mxbai-embed-large-v1)plpgsql是 PostgreSQL 默认安装的内置扩展,用于写存储过程、触发器、函数vector扩展提供了向量数据类型和相似性搜索功能
启用这些扩展后,我们就可以开始使用 PostgresML 的机器学习功能了。
步骤 6:示例:创建文章表
创建一个用于存储文章的表,其中包含一个用于嵌入的 VECTOR(384) 列,适用于像 sentence-transformers/all-MiniLM-L6-v2 这样的模型:
表结构设计
1 | CREATE TABLE articles ( |
创建索引优化查询
1 | -- 为常用查询字段创建索引 |
表结构说明
- id:主键,自增序列
- title:文章标题,必填字段
- summary:文章摘要,用于生成嵌入向量
- publication_date:发布日期,便于时间范围查询
- summary_embedding:384维向量,存储文本嵌入
- category:文章分类,便于分类查询
- tags:标签数组,支持多标签分类
- author:作者信息
- view_count:浏览量统计
- created_at/updated_at:时间戳记录
插入示例数据
请插入 20 篇与电子商务相关的文章示例:
1 | INSERT INTO articles (title, summary, publication_date, category, tags, author) VALUES |
验证数据插入
1 | -- 查看所有文章 |
数据质量检查
1 | -- 检查是否有缺失的摘要 |
步骤 7:使用 pgml.embed 生成嵌入
使用 pgml.embed 函数为摘要列生成词嵌入。sentence-transformers/all-MiniLM-L6-v2 模型速度快,可生成 384 维词嵌入,并且对于小型数据集来说可靠:
嵌入生成基础操作
1 | UPDATE articles |
操作完成后,
summary_embedding字段存储向量化数据:
模型选择说明
PostgresML 支持多种文本嵌入模型,每种模型都有其特点:
| 模型名称 | 维度 | 大小 | 特点 | 适用场景 |
|---|---|---|---|---|
sentence-transformers/all-MiniLM-L6-v2 | 384 | 23MB | 速度快,轻量级 | 通用文本嵌入 |
BAAI/bge-small-en-v1.5 | 512 | 33MB | 质量高,支持中文 | 中英文混合文本 |
sentence-transformers/all-mpnet-base-v2 | 768 | 110MB | 高质量,较大 | 高精度语义搜索 |
intfloat/multilingual-e5-small | 384 | 24MB | 多语言支持 | 多语言环境 |
批量生成嵌入
对于大量数据,建议使用批量处理以提高效率:
1 | -- 分批处理,避免内存问题 |
监控嵌入生成进度
首次使用时,由于模型(约 23MB)需要从 Hugging Face 下载,因此处理 20 行数据可能需要几秒到几分钟。请检查进度:
1 | -- 检查已生成嵌入的文章数量 |
验证嵌入质量
1 | -- 验证嵌入是否成功生成 |
预期输出:
1 | id | title | embedding_dimension | has_embedding |
嵌入向量分析
1 | -- 计算嵌入向量的统计信息 |
错误处理和重试机制
如果嵌入生成失败,可以使用以下方法处理:
1 | -- 创建错误记录表 |
模型切换和对比
如果嵌入速度慢或失败(例如,由于网络问题),请尝试使用替代模型:
1 | -- 使用 BAAI/bge-small-en-v1.5 模型(支持中文) |
嵌入缓存管理
PostgresML 会自动缓存下载的模型,但你可以手动管理缓存:
1 | -- 查看已缓存的模型 |
现在我们已经为列摘要设置了嵌入,可以进入下一步的语义搜索操作。
步骤 8:使用 pgvector 执行语义搜索
使用 pgvector 的余弦距离运算符 (<=>) 进行语义搜索。例如,使用同一模型查找与”无线技术趋势”相关的文章:
基础语义搜索
1 | -- 查找与"无线技术趋势"相关的文章 |
预期输出:
1 | id | title | summary | publication_date |
语义搜索原理
语义搜索基于向量相似度计算,主要使用以下运算符:
| 运算符 | 描述 | 适用场景 |
|---|---|---|
<=> | 余弦距离 | 文本相似度,方向向量比较 |
<-> | 欧氏距离 | 数值向量,几何距离 |
<+> | 曼哈顿距离 | 网格路径,特征差异 |
带相似度分数的搜索
1 | -- 查找相似文章并显示相似度分数 |
多条件语义搜索
1 | -- 结合分类和语义搜索 |
时间范围语义搜索
1 | -- 在特定时间范围内进行语义搜索 |
标签相关的语义搜索
1 | -- 查找包含特定标签的相似文章 |
搜索结果分页
1 | -- 实现搜索结果分页 |
搜索结果过滤
1 | -- 过滤低相似度的结果 |
多关键词语义搜索
1 | -- 使用多个关键词进行综合语义搜索 |
搜索统计和分析
1 | -- 分析搜索结果分布 |
搜索性能优化
1 | -- 使用 CTE 优化复杂搜索 |
这些搜索技术可以应用于各种实际场景,如:
- 内容推荐系统:基于用户查询推荐相关文章
- 智能搜索:理解用户意图,返回语义相关的结果
- 知识库检索:在海量文档中快速找到相关内容
- 问答系统:为用户问题找到最相关的答案候选
步骤 9:优化和扩展
对于较大的数据集,创建索引可以加快搜索速度:
向量索引创建
1 | -- 创建 IVFFlat 索引(适合大规模数据集) |
索引类型对比
| 索引类型 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| IVFFlat | 构建快,内存占用少 | 查询精度较低 | 大规模数据集,近似搜索 |
| HNSW | 查询精度高,速度快 | 构建慢,内存占用大 | 高精度要求,中小规模数据集 |
索引参数优化
1 | -- IVFFlat 索引参数说明 |
索引维护
1 | -- 查看索引信息 |
数据库性能优化
1 | -- 配置 PostgreSQL 参数 |
查询性能监控
1 | -- 启用查询分析 |
内存和缓存优化
1 | -- 调整 PostgreSQL 内存参数 |
数据分区策略
1 | -- 按时间分区(适用于时间序列数据) |
PostgresML 控制面板
访问 http://127.0.0.1:8888 即可查看 PostgresML 控制面板,了解查询和数据可视化效果。
控制面板功能
- 数据浏览:查看数据库中的表和数据
- 查询测试:在线测试 SQL 查询
- 性能监控:查看查询性能指标
- 模型管理:管理机器学习模型
- 可视化:向量搜索结果可视化
控制面板故障排除
如果无法加载控制面板:
1 | # 检查容器日志 |
生产环境部署建议
- 高可用性:使用 PostgreSQL 主从复制
- 负载均衡:使用 pgpool 或 HAProxy
- 监控告警:配置 Prometheus + Grafana
- 备份策略:定期备份数据和配置
- 安全配置:使用 SSL/TLS 加密连接
- 资源限制:设置合适的 CPU 和内存限制
故障排除和最佳实践
常见问题及解决方案
1. 容器启动问题
问题:容器启动失败或立即退出
1 | # 检查容器日志 |
2. 数据库连接问题
问题:无法连接到 PostgreSQL 数据库
1 | # 检查数据库连接 |
3. 扩展安装问题
问题:无法创建 pgml 或 vector 扩展
1 | -- 检查 PostgreSQL 版本 |
4. 模型下载问题
问题:嵌入生成失败或速度很慢
1 | -- 检查网络连接 |
5. 内存不足问题
问题:容器或数据库因内存不足而崩溃
1 | # 监控内存使用 |
性能优化最佳实践
1. 索引优化
1 | -- 选择合适的索引类型 |
2. 查询优化
1 | -- 使用 CTE 减少重复计算 |
3. 数据管理
1 | -- 定期清理过期数据 |
生产环境部署建议
1. 安全配置
1 | # 使用强密码 |
2. 监控和告警
1 | # 使用 Prometheus 监控 |
3. 备份策略
1 | # 定期备份数据 |
开发和测试建议
1. 开发环境
1 | # 使用 Docker Compose 管理开发环境 |
2. 测试策略
1 | -- 创建测试数据 |
常见错误代码和解决方案
| 错误代码 | 描述 | 解决方案 |
|---|---|---|
28P01 | 认证失败 | 检查密码和 pg_hba.conf |
58P01 | 磁盘空间不足 | 清理磁盘空间或增加存储 |
53300 | 连接过多 | 增加 max_connections |
XX000 | 内部错误 | 重启容器或检查日志 |
日志分析
1 | # 查看容器日志 |
通过遵循这些故障排除和最佳实践指南,你可以确保 PostgresML 在生产环境中稳定运行,并充分发挥其性能潜力。
故障排除与最佳实践
常见问题诊断
1. 容器启动失败
问题症状:
1 | docker ps -a | grep pgml_postgres |
诊断步骤:
1 | 查看容器详细状态 |
解决方案:
1 | 停止冲突服务 |
2. 数据库连接失败
问题症状:
1 | psql: error: connection to server at "localhost" (5434) failed: |
诊断步骤:
1 | -- 在容器内检查 PostgreSQL 状态 |
解决方案:
1 | -- 修改 PostgreSQL 配置 |
3. 扩展安装失败
问题症状:
1 | ERROR: could not open extension control file for "pgml": No such file or directory |
诊断步骤:
1 | -- 检查扩展可用性 |
解决方案:
1 | -- 重新安装扩展(如果支持) |
性能优化建议
1. 索引优化策略
1 | -- 选择合适的索引类型 |
2. 查询性能优化
1 | -- 使用 EXPLAIN ANALYZE 分析查询 |
3. 生产环境部署建议
1 | # docker-compose.yml 示例 |
安全最佳实践
1. 访问控制
1 | -- 创建只读用户 |
2. 数据备份与恢复
1 |
|
参考资料





























